Transforming Data
Conceptual Model
Open Data Fabric clearly separates two types of data:
- Source - represented by root datasets this data comes directly from external systems, with party that owns the dataset having complete authority over the data and fully accountable for its veracity
- Derivative - represented by derivative datasets this data is produced by transforming and combining other datasets (root or derivative).
In simple terms, given two root datasets A and B the derivative dataset C can be though of as a pure function:
C = f(A, B)
Unlike databases, or most data processing libraries you might’ve used ODF is not “batch”, but stream-oriented. So A, B here are both potentially infinite data streams, and function f() is a streaming (temporal) processing operation that produces another stream as an output.
Stream processing composition works just like normal functional composition:
D = h(C) = h(f(A, B))
F = g(D, E) = g(h(f(A, B)), E)
This allows us to build infinitely complex data processing pipelines and supply chains in the form of a Directed Acyclic Graph (DAG):
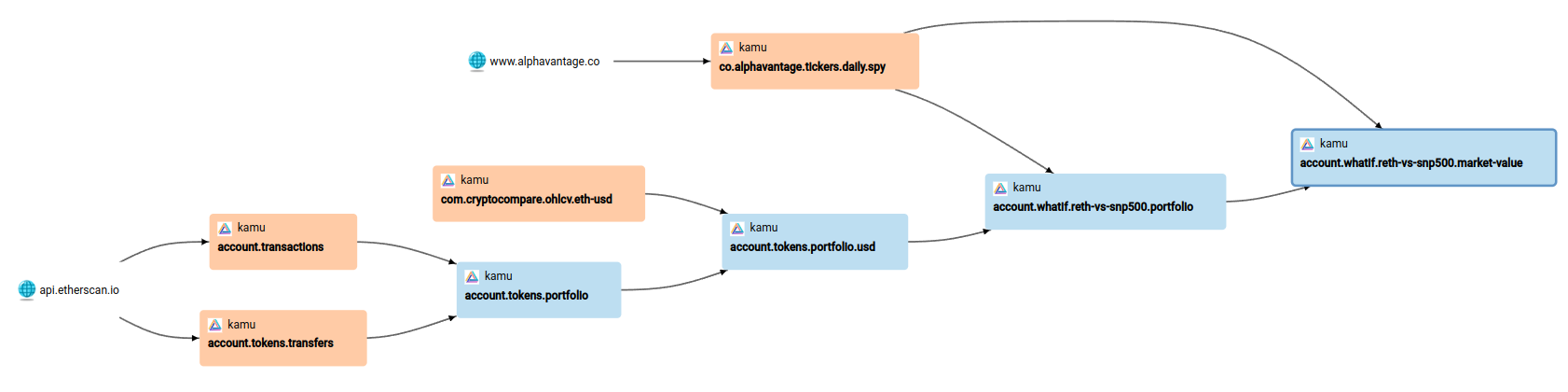
Functions being “pure” means that derivative datasets don’t depend on any information outside of ODF - you cannot call arbitrary APIs or download files as part of such processing.
While this may seem restrictive - this unlocks highly desirable properties like reproducibility and verifiability of all computations and ability to automatically derive provenance.
Creating Derivative Datasets
Derivative datasets are created by specifying the SetTransform metadata event.
Example:
kind: DatasetSnapshot
version: 1
content:
name: my.trading.holdings
kind: Derivative
metadata:
- kind: SetTransform
# Using one dataset as an input
inputs:
- datasetRef: my.trading.transactions
transform:
# Using Apache Flink SQL engine to perform cumulative sum streaming aggregation
kind: Sql
engine: flink
query: |
SELECT
event_time,
symbol,
quantity,
price,
settlement,
sum(quantity) over(partition by symbol order by event_time rows unbounded preceding) as cum_quantity,
sum(settlement) over(partition by symbol order by event_time rows unbounded preceding) as cum_balance
FROM `my.trading.transactions`
This event is as simple as defining two things:
inputs- data from which datasets will be used as input to this pipeline steptransform- the transformation being performed.
Technically ODF supports any data processing framework. You will see a lot of Streaming SQL in our examples as we believe it currently offers best user experience when defining streaming transformations.
Execution Model
When you use kamu pull on a derivative dataset the tool will:
- Start the appropriate query engine
- Restore the state of computation from previous checkpoint (if any)
- Feed the previously unseen data from all inputs
- Write results into a new data slice
- Suspend the computation state into a new checkpoint
- Write a new metadata block
Note that query engines see input data only once. When performing things like windowed aggregations the intermediate state of computations between the suspends is stored in checkpoints.
Supported Operations
Some typical operations you can perform on datasets (in the order of increasing complexity) are:
- Map - performing computation on one record at a time
- Filter - deciding whether to include a record in the output based on some condition that considers only one record at a time
- Aggregation - combining values of multiple records together based on some grouping function (e.g. a time window)
- Projection - an aggregation aimed at reducing dimensionality of data
- Stream-to-Stream Join - combining several streams of data based on some predicate and a time window
- Temporal Table Join - joining a stream to a projection of another stream that represents “current state” of some evolving data based on the timestamp of individual records.
Please see Examples for detailed explanation of each of these classes of operations.
Consistency
Modern stream processing frameworks should be more appropriately called “temporal processing frameworks” as they account for time of records and all kinds of time-related problems during the computations.
Transparently to the user streaming can handle situations like:
- Late arrivals and backfills
- Out-of-order arrivals
- Phase shift and differences in data arrival cadences when joining several streams
Unlike batch that has no notion of time, streaming is a more complete processing model that provides you complete control over the tradeoff between consistency and latency.
See Kamu Blog: The End of Batch Era to learn more.
Self-correcting Nature
While we mostly talk about data streams from perspective of observing new events and adding new records - there are many situations when events that were already published may be deemed incorrect and need to be retracted or corrected.
We previously discussed retractions and corrections in the context of merge strategies, but the most amazing thing about stream processing is that it can automatically react to retractions and corrections in inputs to issue appropriate retractions or corrections in the output.
This means that whenever a major issue is detected and fixed in some root dataset - these events can automatically and rapidly propagate through hundreds of data pipeline stages with no human involvement.
See Retractions & Corrections section for a deeper look.