Ingesting Data
Ingestion is the process by which external data is added into Open Data Fabric’s root datasets. Kamu supports a wide variety of sources including resources on the web and blockchains. Below we will describe why this process is necessary and how it works.
Motivation
When interacting with data on the web we usually cannot make any assumptions about guarantees that its publisher provides:
- Just by looking at the data we cannot tell if it is mutable or preserves history of changes
- We often can’t tell where it originates from and who can be held accountable for its validity
- We can’t be sure that it’s sufficiently replicated, so that if the server that hosts it today disappears tomorrow - all our data science projects will not be left non-reproducible.
Data on the web is in a state of a constant churn where data is often updated in destructive ways and even important medical datasets disappear over night. Any guarantees do exist are hidden behind many layers of service agreements, yet still provide us no strong assurance that they won’t be violated (on purpose or by accident). This is why step #1 of every data science project is to copy and version the data.
Open Data Fabric was created to avoid excessive copying and harmful versioning of data, and instead embed these guarantees into the data format itself, making them impossible to violate.
Ingestion step is about getting the external data from this “churning world” into strict ledgers of root datasets, where properties like clear ownership, reproducibility, accountability, and complete historical account can be guaranteed and made explicit.
Sources
There are two types of ingestion sources:
- Push sources - for cases when external actor actively sends data into a dataset. This is suitable e.g. for IoT devices that periodically write data, business processes that can report events directly into ODF dataset, or for ingesting data from streaming data APIs and event queues like Apache Kafka.
- Polling source - for cases when external data is stored somewhere in bulk and we want to synchronize its state with ODF dataset periodically. This is suitable e.g. for datasets that exist as files on the web or for reading data from bulk APIs.
Phases
Ingestion process has several well-defined phases:
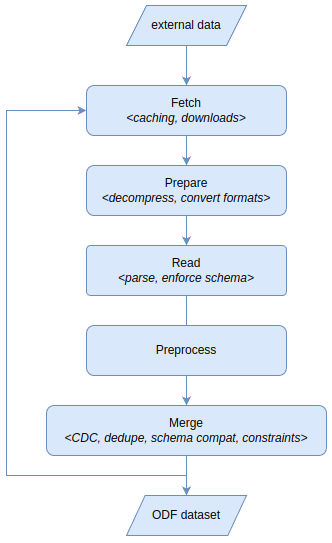
These phases are directly reflected in the SetPollingSource event:
fetch- specifies how to download the data from some external source (e.g. HTTP/FTP) and how to cache it efficientlyprepare(optional) - specifies how to prepare raw binary data for reading (e.g. extracting an archive or converting between formats)read- specifies how to read the data into structured form (e.g. as CSV or Parquet)preprocess(optional) - allows to shape the structured data with queries (e.g. to parse and convert types into best suited form wit SQL)merge- specifies how to combine the read data with the history of previously seen data (this step is extremely important as it performs “ledgerization” / “historization” of the evolving state of data - see Merge Strategies section for explanation).
SetPollingSource event is - please refer to First Steps section that explains dataset creation.The phases of push ingest are defined by the AddPushSource
event and are very similar, except for omitting fetch and prepare steps.
For more information refer to Polling Sources and Push Sources sections.
Further Reading
- For more information about defining data sources refer to Polling Sources and Push Sources sections.
- For examples of dealing with various types of data refer to Input Formats section.
- For detailed explanation of “ledgerization” process see Merge Strategies section.
- For more inspiration on creating root datasets see Examples and
kamu-contribrepo.